Se o título atraiu você provavelmente você está familiarizado com o termo serverless, mas para introduzir a galera que caiu de paraquedas por aqui, serverless é uma arquitetura na qual nós “não precisamos” de servidores para hospedar nossos códigos. Nós simplesmente escrevemos os nossos códigos, escolhemos um player do mercado e colocamos o código lá. Depois é só chama-lo e tá feito! Você pode entender melhor sobre serverless nesse artigo que eu escrevi aqui no blog: Como hospedar seu app sem servidor?
Feita a introdução, vamos ao objetivo!
Calcular a execução de uma função na arquitetura serverless pode ser uma tarefa extremamente difícil, isso porque os principais players do mercado estruturaram seu modelo de negócios baseado em tempo de execução dessa função, o que é extremamente justo, mas o valor “pode” ser salgado dependendo de várias variantes.
1 – Tempo de execução
Partindo dessa premissa, você como programador, precisa garantir que o código vai perder menos tempo possível, afinal de contas, mais do que nunca o termo “time is money” se aplica nesse caso.
Muitas tecnologias podem ser adotadas por aqui, algumas bem simples como a utilização de um try/catch na chamada de suas funções ou simplesmente usando uma linguagem de programação compilada como o Go, que faria seu código rodar mais rápido, consumir menos recursos e consequentemente gastar menos dinheiro.
Além das técnicas já citadas não podemos esquecer da utilização do paradigma de desenvolvimento funcional para as linguagens que suportam esse tipo de desenvolvimento com certeza é um ponto para observarmos. Em Javascript por exemplo existe um ganho considerável apenas utilizando as abstrações existentes como map, filter e reduce. Além disso, são essas técnicas que propiciam que softwares de análise de big data como o Apache Hadoop funcionem.
2. Infraestrutra
Não só de máquinas e cabos são feitas as estruturas de uma organização, seja essa estrutura on promisses (instalada localmente na sua empresa) ou na nuvem (cloud computing) precisa de um time para orquestrar todos aqueles servidores que você suou para pagar ou para convencer sua diretoria a pagar.
Por mais que ainda vejamos muitos casos em que empresas ainda utilizem infraestrutura de datacenter local, seja por regras governamentais, seja por necessidade de disponibilidade imediata (altíssima latência), softwares não projetados para escalar em nuvem, ou qualquer outro motivo (eu poderia passar horas por aqui hehe), já sabemos que essa prática é tem um peso muito grande a ser carregado. Máquinas depreciam, tem um custo elevado e normalmente tem capacidade ociosa.
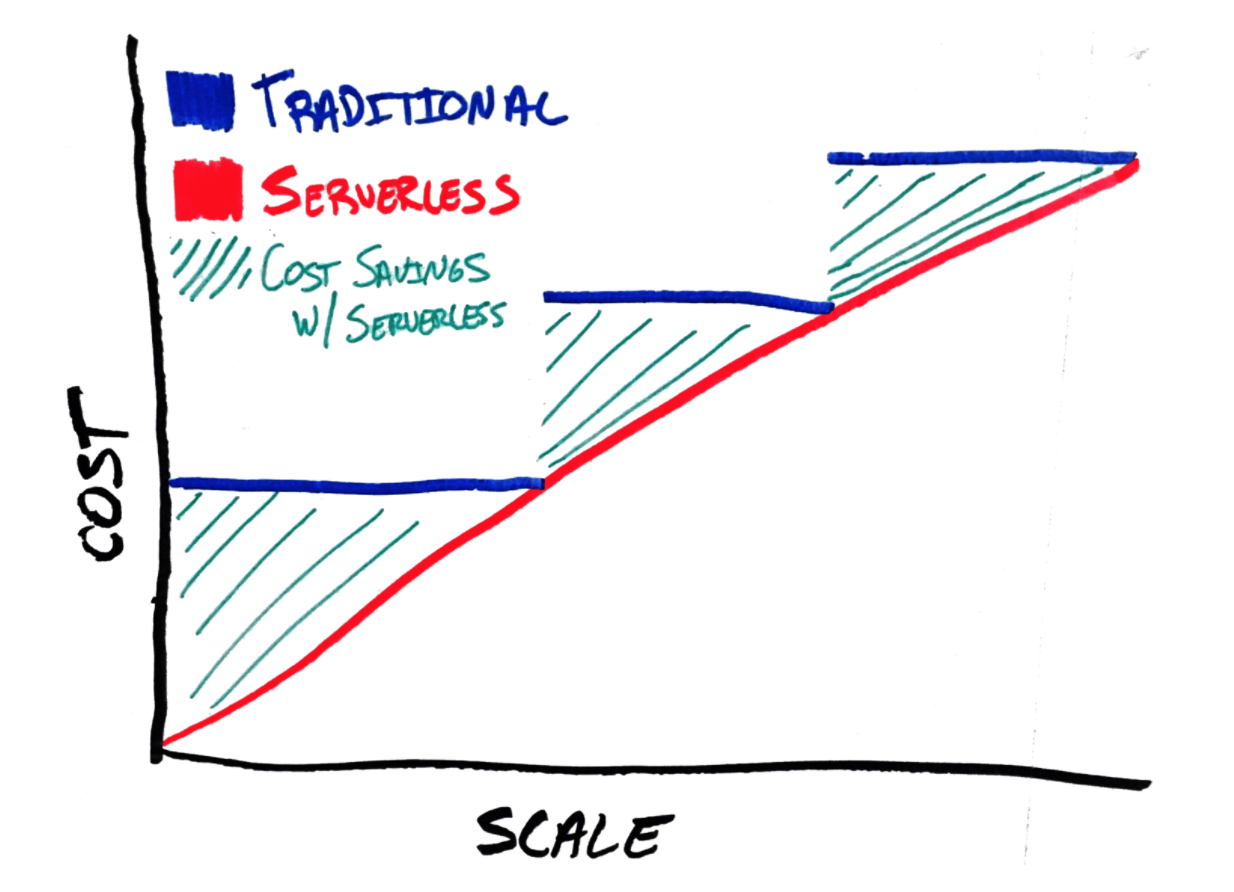
Em se tratando de máquinas, imagine que você tem um software hospedado em nuvem pública em uma máquina virtual. Você tem todos as buzz words de tecnologias configuradas no melhor player do mercado com alta performance e redundância configurados num nível nunca visto antes. Você se sente super feliz com isso! Eu também me sentiria. Entretanto, mesmo que podendo adicionar memória, processamento e disco quando lhe der vontade ou quando a máquina precisar, você não pode adicionar apenas hipotéticos 123 Mhz de processamento, você tem uma quantidade pré-definida pelo seu serviço de hospedagem na qual é possível adicionar, sem contar os reboots que seriam necessários, você certamente está perdendo dinheiro com capacidade ociosa, mesmo que pouca, você está perdendo dinheiro.
Com a utilização de serverless, a sua função é chamada, ele faz o que tem que fazer em um tempo X e te devolve o resultado. Pronto! Usou? Pagou pelo que usou.
Tenho uma longa carreira na área de infraestrutura e sempre foi um desafio propor para a direção o aumento da capacidade computacional do datacenter, isso porque normalmente era visto exatamente dessa forma que eu estou colocando aqui: desperdício de recursos financeiros (apesar de ser cobrado quando a coisa parava heheh) e como exemplo posso citar também a capacidade ociosa que existe, principalmente em estruturas on promisses com máquinas físicas, onde você tem uma máquina que suporta 100 usuários, sua empresa cresce e você tem 110 usuário, você não consegue comprar uma máquina que suporte 10 usuários (e também não faria sentido não ter margens de crescimento nesse paradigma), talvez, você precisará comprar outra(s) máquina(s) que suportem 100 usuários e pagar esse spread ocioso de recursos.
3. Pessoas, mais especificamente: DEVOPs
Não é uma caça as bruxas, nem a extinção desse profissional, muito pelo contrário. Esses caras sempre foram extremamente importantes e são ainda mais hoje em dia.
A questão aqui é que mesmo utilizando tudo em nuvem, se você não tem conhecimento suficiente para orquestrar o ambiente onde roda a sua aplicação, você vai ter que contratar alguém para fazer isso por você, justo! Mas porque ter esse custo e ainda ter todos os custos de ociosidade que eu comentei ali em cima se eu posso não ter?
Cabe ressaltar que dependendo do nível e do tamanho da aplicação é extremamente importante que você estruture e a mantenha com um DEVOP, mesmo utilizando serverless.
4. Performance
Imagine você que em um dia extremamente atípico o seu e-commerce, principal canal de vendas do seu negócio, teve, ao invés dos 5 mil acessos diários, 1 milhão de acessos que repercutiu em vendas e visibilidade para o seu negócio. A sua infraestrutura sem serverless, on promisses ou na nuvem, suportaria essa demanda sem quebrar? Sem ficar lenta ou indisponível? Ora, responde eu mesmo: provavelmente não!
Com o serverless, você com certeza vai pagar por essa demanda (e bastante), mas o seu usuário não será impactado por qualquer um desses fatores, já que estamos falando de players como Amazon Lambda, Microsoft Azure Functions e Google Cloud Functions por exemplo. Acho que temos bastante capacidade computacional com esses caras, certo?
5. Planos gratuitos
Pensando como uma startup todo o centavo é muito importante e se conseguimos economizá-los, isso se reverte em café em cima da mesa, café se transforma e código-fonte e por aí vai…
Brincadeiras à parte, a maioria dos players, grandes ou não, oferecem planos gratuitos, claro que com suas limitações, mas certamente atende as suas demandas de teste, MVP e lançamento do seu produto.
Conclusão
Serverless ainda é caro, complexo de ser medido e provisionado (valores monetários), mas assim como vários outros aspectos da sua startup, precisa ser analisado com atenção, principalmente aos fatores indiretos ligados a sua implementação. Também é necessário ficar atento à operação continuada e entender o momento certo de migração, caso necessário. Isso pode ser um fator muito importante dentro da sua organização.
Eu uso serverless como premissa da minha estrutura e você?
Gostou do artigo? Consegui agregar valor para você? Se sim, indique para um amigo para que ele também fique esperto no assunto.
Obrigado por vir até aqui.
Vamos fazer coisas incríveis hoje?